監視ツールは十分なのに、毎回ダッシュボードを開いて自分で状況を読み解いていませんか。
この記事では、XDAのShekhar Vaidya氏が実践した「既存の監視基盤の上にローカルLLMの解釈層を載せる」自宅サーバー運用の事例を整理します。クラウドLLMのコストやプライバシー負担を避けながら、ログとメトリクスを人間向けの答えに変える方法がわかります。
この記事でわかること
- 監視ダッシュボードだけでは足りない「解釈」の部分
- Portainer・Beszel・Uptime KumaとGemma 4を組み合わせる構成
- 停止コンテナのログから見つかった、通知されない軽微な障害
- Pythonスクリプトとntfyで2時間ごとに要約を届ける自動化
データは揃っているのに、答えがない
自宅サーバー(ホームラボ)運用では、コンテナが増えるほど監視も増えます。Uptime Kumaで公開サービスの死活を見、Portainerでコンテナの起動状態を確認し、BeszelでCPUやRAMの負荷を追う。Vaidya氏もこの3つを使い分けていました。
問題は「見える化」ではありません。ダッシュボードは停止中のコンテナが3つあること、RAMが逼迫気味であることまでは教えてくれます。しかし、その3つが致命的か無視してよいか、RAM圧迫と停止コンテナに因果関係があるかは、結局人間が判断しなければなりません。
以前はClaudeなどのクラウドLLMにサーバー情報を渡して分析させる試みもありました。数日でコスト、プライバシー、外部依存の負担が目立ち、結局ダッシュボードに戻っていました。自宅運用の「できるだけローカル」という方針とも噛み合いませんでした。
解釈層としてのローカルLLM
転機は、すでに手元で動かしていたGemma 4を監視データに向けたことです。Gemma 4はGoogleが2026年4月に公開したオープンウェイトのモデル群で、E2B・E4B・26B・31Bの4サイズがあります。エージェント的なワークフローや構造化出力にも対応し、Ollama経由でローカル実行できます。
Vaidya氏の環境では、24コンテナが動く古いDellサーバーにLLMは載せていません。推論はRTX 4070 Ti搭載のゲーミングPC上のOllamaが担います。8BクラスのモデルはVRAMを多く使うため、すでに24コンテナを回すサーバー本体に載せるのは現実的ではない、という判断です。常時起動のPCにモデルを置くことで、ホームラボ側の負荷は増やさずに解釈層だけを追加できました。
データの流れは次のとおりです。
- PortainerのAPIからコンテナ状態とログを取得
- BeszelのAPIからホストのリソース指標を取得
- プロキシスクリプトがブラウザと各APIを中継
- 取得データをGemma 4に渡し、自然言語で質問・要約
PortainerはCORS(ブラウザから別オリジンへのアクセス制限)が厳しいため、Docker設定をいじらずに済むよう小さなプロキシを挟んでいます。クラウドAPIキーや外部送信は使わず、すべてローカルネットワーク内で完結します。
ダッシュボードでは見えなかったログの意味

PortainerはDockerコンテナの一覧表示、起動・停止、ログ閲覧をブラウザから行える管理ツールです。Vaidya氏はここから停止コンテナのログを初回に一括取得し、稼働中コンテナのログはチャットから必要なときだけ取る運用にしました。
ログは本来あふれています。正常稼働中のコンテナログを毎日読む人はほとんどいません。停止コンテナのログを開いても、数百行から手がかりを探す作業になりがちです。
Gemma 4にログを渡すと、公開向けサービス(Jellyfin、Immich、Vaultwardenなど)は稼働中である一方、Uptime KumaのログからVaultwardenの外部タイムアウトやNextcloudの断続的な503エラーを拾えました。どちらもアラート閾値には届かない軽微な事象で、だからこそダッシュボードだけでは見逃していた、というのがVaidya氏の報告です。
「モデルがログを読める」こと自体は新しくありません。変わったのは、ログが「障害後にだけ開くファイル」から「定期的に意味づけされる情報源」になった点です。
BeszelとUptime Kumaはそのまま活かす
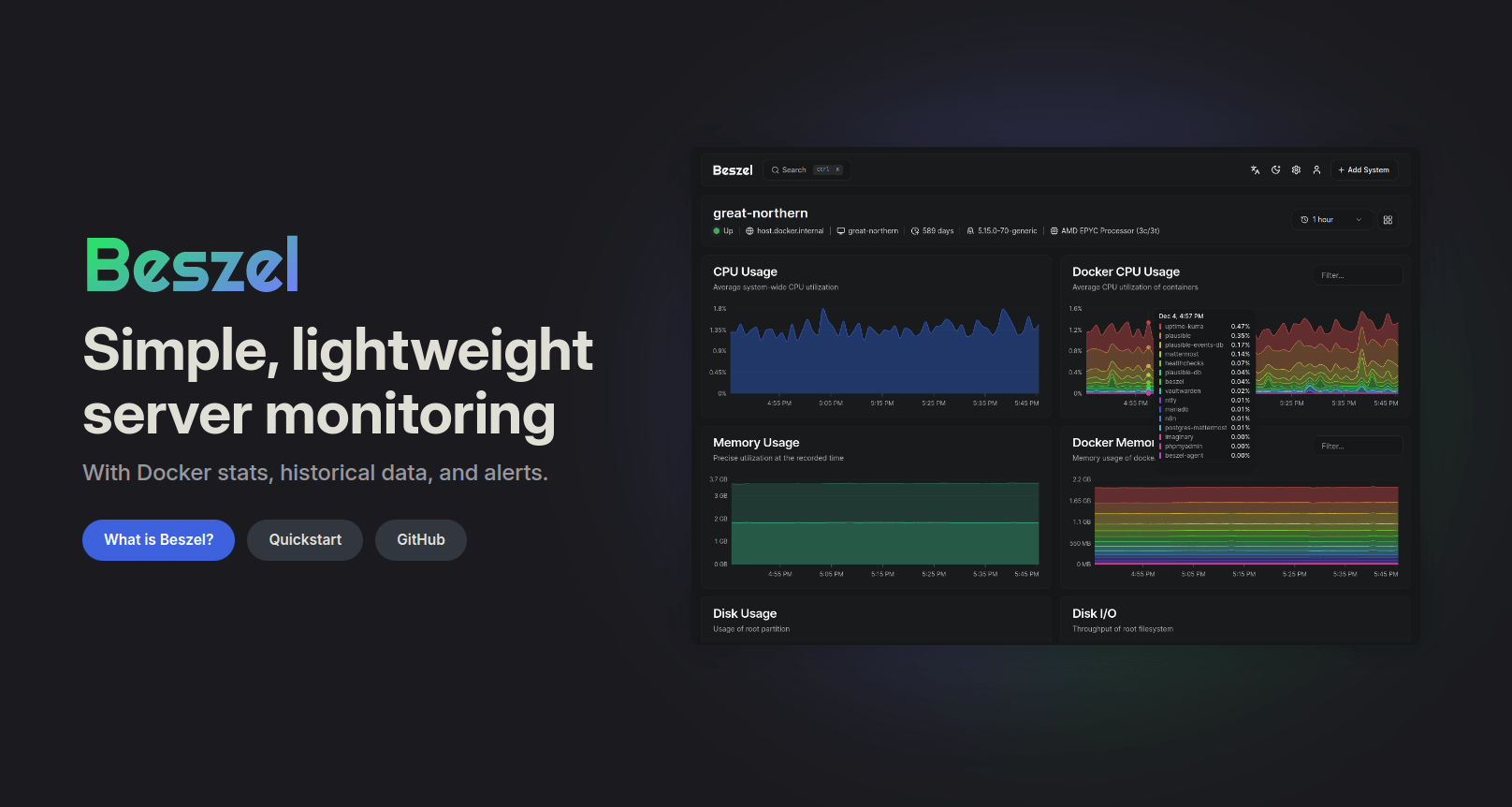
BeszelはCPU、RAM、ディスク、ネットワーク、コンテナ単位のDocker統計を記録する軽量なサーバー監視ツールです。ホストの健康状態を時系列で追うのに向いています。
Uptime KumaはHTTP、TCP、DNS、SSL証明書など外部からの到達性を監視するセルフホスト型の死活監視ツールです。Beszelが「サーバーの中」を見るなら、Uptime Kumaは「外から見えるか」を見ます。
Vaidya氏はこの2つを廃止していません。収集と可視化は従来どおり各ツールの得意分野に任せ、LLMはその上に「いま何に注意すべきか」を言語化する層として置いています。RAM圧迫と停止コンテナの関連があるか、今すぐ対応が要る事象があるか、といった平文の質問に答えられるようになった、と報告しています。
手動確認からスマホ通知へ
チャット画面を開く手間さえ残っていたため、次の段階でヘッドレスのPythonスクリプトを追加しました。1回の実行でPortainerとBeszelを問い合わせ、停止コンテナのログを取得し、Gemma 4にプロンプトを送り、結果をntfy経由でスマホに届けます。ntfyはセルフホストも可能なプッシュ通知サービスです。
Windowsのタスクスケジューラで、ログイン時とログイン中は2時間ごとにスクリプトを走らせています。注意が必要な事項だけ強調された要約が届くため、PortainerやBeszel、Uptime Kumaを毎回開く頻度は大きく下がった、とVaidya氏は述べています。
以前は自作の監視スクリプトを次々書いていました。それらが解いていたのは、結局「生データを人間が理解できる形に翻訳する」問題でした。LLMがその翻訳を担えるようになってからは、新しい条件分岐スクリプトを書くより、質問を変える方が速くなった、というのが事例の結論です。
自宅運用に応用するときの着眼点
この事例の本質は、特定製品の入れ替えではなくレイヤーの追加です。監視ツールはデータ収集とアラートに集中し、ローカルLLMは文脈付きの要約と優先度判断を担う。クラウドLLMを使わずOllamaとGemma 4を選んだことで、ログ内容が外部に出ない運用も維持できています。
再現するなら、まず手元で動くローカルLLM(VRAMに収まるサイズを選ぶ)と、すでに使っている監視ツールのAPIをつなぐ小さなプロキシから始めるのが現実的です。停止コンテナのログを定期投入し、「今対応が要るか」を一文で返させるだけでも、ダッシュボード巡回の負担はかなり減ります。GPU付きの別マシンに推論を逃がす構成は、コンテナをたくさん載せた低スペックサーバーでもそのまま真似できます。
Vaidya氏の環境では、要約がスマホに届くようになってからは、わざわざ質問しなくても答えが来る状態まで進んでいます。監視の課題が「データ不足」ではなく「解釈のボトルネック」だった、という整理は、同様のホームラボ構成を持つ読者にもそのまま当てはまるでしょう。